
هل يستطيع الذكاء الاصطناعي التفكير؟
ماذا يعني أن تكون الآلة ذكية؟
جعل الآلات “ذكية” يتطلب، من بين أمور أخرى، تمكينها من اتخاذ القرارات. صُممت برامج الذكاء الاصطناعي المبكرة لأداء مهام محددة – على سبيل المثال، معرفة كيفية لعب الشطرنج ♟️.
لنتذكر أنه في عام 1997، تغلّب برنامج الذكاء الاصطناعي من ابتكار IBM على غاري كاسباروف، بطل العالم في الشطرنج، في مباراة.♟️
كيف تعلم الذكاء الاصطناعي، حتى في شكله البدائي، لعب الشطرنج؟ يرجع ذلك إلى أنه استخدم طريقة تعلم تُعرف بالذكاء الاصطناعي المعتمد على المعرفة. في هذا النهج، تم تدريب الذكاء الاصطناعي باستخدام مجموعة محددة مسبقًا من القواعد وسيناريوهات اللعبة المحتملة. من خلال تحميل الآلة بجميع حالات اللعبة الممكنة وقواعدها، كان بإمكانها تحليل الوضعيات وحساب التحركات للعب بشكل مثالي، ما كان يضمن الفوز أو الاقتراب منه في أغلب الأحيان.
ومع ذلك، عندما ننظر إلى ما هو أبعد من المشكلات المنظمة مثل الشطرنج وننظر إلى مهام أكثر تعقيدًا في العالم الواقعي- مثل التشخيصات الطبية أو التنبؤ بالهاتف الذكي التالي الذي سيشتريه المستهلك – تتضح حدود الذكاء الاصطناعي المعتمد على المعرفة التقليدية. في هذه المجالات، يكون عدد المتغيرات هائلاً وغالبًا ما يكون غير قابل للتنبؤ.
على سبيل المثال، يجب على الطبيب اتخاذ قرارات بناءً على عدد لا يحصى من العوامل: تاريخ المريض، الأعراض، ونتائج الفحوصات. لهذا السبب، فشلت تدريبات الذكاء الاصطناعي المعتمدة على المعرفة في النهاية في العديد من المجالات؛ إذا لا يمكن لنظام الذكاء الاصطناعي التعامل مع التعقيدات والمتغيرات اللامتناهية الموجودة في العالم الواقعي.
كيف يتعلم الذكاء الاصطناعي الذي نعرفه اليوم؟
الذكاء الاصطناعي كما نعرفه اليوم يتعلم من خلال مراقبة كميات هائلة من البيانات (البيانات الضخمة) واستخدام الخوارزميات الرياضية لاكتشاف الأنماط داخل تلك المعلومات، مُحاكيًا بذلك طريقة عمل الدماغ البشري (الشبكات العصبية). وهذا يؤدي إلى نوع جديد من التعلم، يُعرف باسم التعلم العميق. ويشبه هذا النوع من التعلم الطريقة التي يتحسن بها الإنسان من خلال الممارسة: عن طريق تكرار المهام وتصحيح الأخطاء على طول الطريق.
أنواع تعلم الذكاء الاصطناعي:
-
التعلم الموجه
كيفية عمله؟
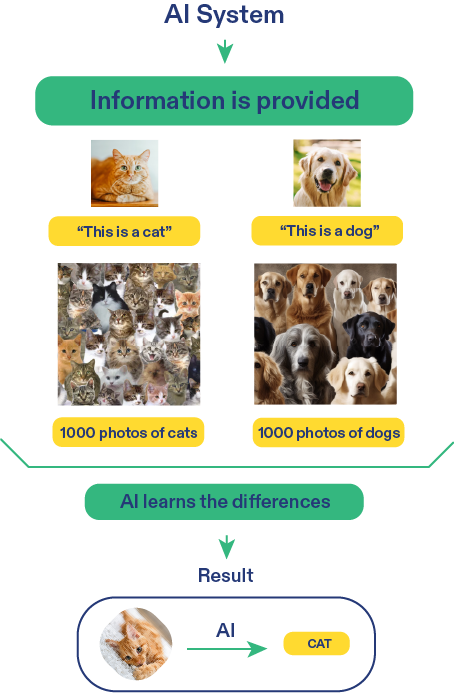
يستقبل النظام أمثلة مصنفة مع الإجابة الصحيحة. باختصار، يقوم شخص ما “بتعليم” الذكاء الاصطناعي من خلال قول “هذا كلب” أو “هذه قطة”. في كل مرة يرتكب فيها النظام خطأً، يقوم بتعديل “عملية التفكير” الخاصة به لتحسين أدائه في المرة القادمة. إنه يشبه طفلاً يتعلم حروف العلة في اللغة الإنجليزية، حيث يكررها حتى يتقنها.
👈 مثال عملي:
- التعرف على الصور: تخيل أن لديك 1000 صورة للقطط و1000 صورة للكلاب، وكلها مصنفة. يقوم نظام الذكاء الاصطناعي بفحص هذه الصور ويتعلم التمييز بين خصائص كل واحدة منها: “إذا كان له آذان مدببة وخطم طويل، فهو كلب.”
- الأخطاء والتصحيحات: إذا قام الذكاء الاصطناعي بتحديد قطة بشكل خاطئ على أنها كلب، فإنه يقوم بتعديل معاييره الداخلية، المعروفة بالأوزان، لتحسين أدائه في المرة القادمة عند عرض صورة مشابهة عليه.النتيجة: بعد تدريب مكثف، يمكنه الاطلاع على صورة جديدة غير مصنفة وتحديد ما إذا كانت قطة أم كلبًا بثقة.
-
التعلم غير الموجه
كيفية عمله؟
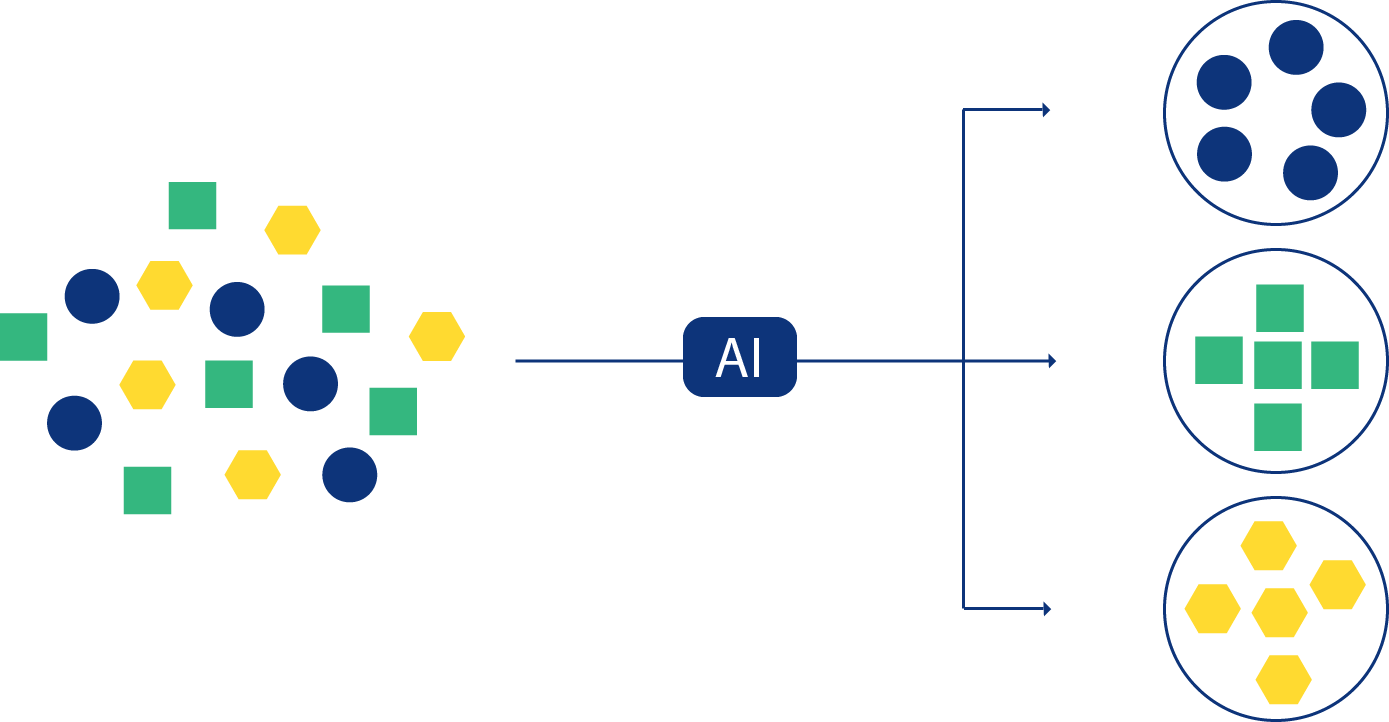
هنا، لا يتلقى الذكاء الاصطناعي بيانات مصنفة. بدلاً من ذلك، يحاول اكتشاف الأنماط أو التجمعات بنفسه. إنه يشبه إعطاء شخص أحجية دون معرفة ما تبدو عليه شكل الصورة النهائية، وتوقع منه أن يقوم بتركيبه من خلال إيجاد القطع التي تتوافق معًا.
👈مثال عملي:
- تقسيم العملاء: تمتلك المتاجر الإلكترونية بيانات حول سلوكيات العملاء (مثل تكرار عملية الشراء، المنتجات المفضلة، ونفقاتهم). بدون تصنيفات، يقوم الذكاء الاصطناعي تلقائيًا بتجميع العملاء حسب السلوكيات المتشابهة. على سبيل المثال، قد يحدد مجموعة من “المشترين المتكررين” وأخرى من “المشترين غير الدائمين”.
- التجميع التلقائي: قد يكتشف الذكاء الاصطناعي، دون تعليمات مسبقة، أن الأشخاص الذين يشترون معدات التخييم غالبًا ما يشترون أيضًا ملابس تقنية.
النتيجة: يمكن للمتجر تقديم عروض ترويجية مخصصة لكل مجموعة بناءً على الأنماط التي اكتشفها الذكاء الاصطناعي.
-
التعلم المعزز
كيفية عمله؟
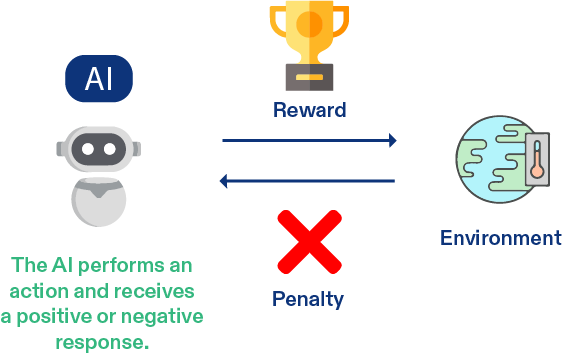
يتعلم هذا النوع من الذكاء الاصطناعي من خلال التجربة والخطأ، بطريقة مشابهة لتعلم الطفل ركوب الدراجة: إذا سقط، فإنه يتجنب ارتكاب نفس الخطأ، وعندما ينجح، يتلقى الثناء. في هذا النموذج، يتلقى الذكاء الاصطناعي مكافآت أو عقوبات بناءً على أدائه، مع الهدف النهائي المتمثل في تحقيق أقصى قدر من المكافآت.
👈مثال عملي:
- مكنسة روبوتية: تخيل روبوتًا يتعلم كيفية التنقل داخل المنزل. إذا اصطدم بالحائط، يتلقى “عقوبة” (نتيجة سلبية). إذا نجح في إيجاد مدخل الباب، يتلقى “مكافأة”. من خلال التجارب المتكررة، يحسّن النظام قدرته على التحرك دون حدوث اصطدامات.
النتيجة: بعد العديد من التجارب، يصبح الروبوت قادرًا على التنقل في المنزل مثل الخبير، مع تحقيق أقصى حد من المكافآت (بتجنب العقبات) وتقليل الأخطاء.
دعنا نلقِ نظرة على مثال للتعلم المدمج في روبوت الدردشة.
يستخدم روبوت الدردشة أنواعًا مختلفة من التعلم:
- التعلم الموجه: يتم تدريبه باستخدام نصوص مصنفة، ويتعلم كيفية الإجابة عن الأسئلة والحفاظ على محادثة مترابطة.
- التعلم غير الموجه: أثناء التدريب، يكتشف أنماطًا في اللغة بمفرده (على سبيل المثال، فهم كيفية استخدام السخرية في الجمل).
- التعلم المعزز: يستمر في تحسين أدائه من خلال تلقي ملاحظات المستخدمين. على سبيل المثال، إذا كانت ردوده غير مفيدة، يمكن تعديل النظام لتجنب تلك الأخطاء.
يتعلم الذكاء الاصطناعي بطريقة مشابهة للإنسان: من خلال مراقبة الأمثلة (التعلم الموجه)، واكتشاف الأنماط بمفرده (التعلم غير الموجه)، أو عن طريق التجربة والخطأ (التعلم المعزز). لكل تقنية استخدام محدد، لكن معًا تمكّن الآلات من التحسين المستمر وزيادة كفاءتها في أداء المهام اليومية، مثل التوصية بالأغاني، أو التعامل مع استفسارات المحادثة، أو قيادة السيارات.
إذا كان الذكاء الاصطناعي يتعلم بطريقة مشابهة للبشر، فهل يمكن أن يكون متحيزًا أيضًا؟ ما نوع المعلومات التي يميل إلى تكرارها؟ لنلقِ نظرة فاحصة.